Dear Rod,
Next year will mark 20 years since I graduated from Coffs Harbour Christian Community High School. I’m sure you’d count me as a success story – I went from Macksville to Cambridge, and a career as a research astrophysicist.
It is with some frustration that I read your recent comments regarding climate change. Firstly, you may want to think about the effect on your students of dismissing Ms Thunberg as a “little girl” (she is 16) and as having “mental problems” (she has Asperger’s syndrome). My recollection is that you treated my classmates and me as young adults, capable and responsible. You would not have been so dismissive if Greta was in one of your classes.
Secondly, you refer to “the predictions of a little girl and false prophets.” You are referring, I presume, to the weight of scientific evidence accumulated by thousands of scientists across the world for decades. I would be happy to bring you up to date. For example, since the beginning of the industrial revolution, the amount of carbon dioxide in the atmosphere has increased by 45%. Carbon dioxide accounts for 10-20% of our atmosphere’s ability to trap heat. Over the last century, sea levels have risen, and the Earth has gotten warmer. These are not prophecies; these are measurements. They are not made by teenagers. They are not made by lone, extreme voices speaking outside their area of expertise, like Paul Ehrlich. They are made by people like me who have dedicated their careers to the study of the natural world. Maybe everything will be fine, but that is far from obvious.
Finally, you seem to imply that climate change will not be a problem because the “world’s future is in the hands of God.” Indeed it is. But God’s plan, for better or worse, was to give humans responsibility for “the fish of the sea and the birds of the air and over every living creature that moves on the ground.” The Bible gives instructions on caring for the land (Lev. 25), and warnings about disobeying those instructions: “you shall sow your seed in vain.” God did not promise to prevent the North American dustbowls of the 1930’s, the tragedy of the Aral Sea, or continuing famines around the world. Our actions have consequences; there is no promise in the Bible that we will be rescued from every effect of our own greed and stupidity.
Yes, the climate change movement contains attention seekers and doomsayers. So does the church. We are also warned about those who cry, “Peace, peace, when there is no peace.” (Jer. 6:14) And yes, scientists have been wrong about all sorts of things in the past. But “some scientists have been wrong in the past, so I’m sure it will turn out that they’re wrong about everything now” is a very risky prophecy. The search for truth and right action needs something between denial and alarm. In the words of Chesterton, we need to hate the world enough to want to change it, and yet love it enough to think it worth changing.
As usual, I’ll be holidaying in Macksville again at the end of the year. I’d be happy to catch up for a chat any time.
Yours,
Luke Barnes




 = Sam is a sharpshooter
= Sam is a sharpshooter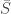 = Sam is not a sharpshooter.
= Sam is not a sharpshooter. = Sam said “I’m going to hit that painted bullseye with this shot”, and then he did.
= Sam said “I’m going to hit that painted bullseye with this shot”, and then he did. = Sam shot at a wall, and then painted a bullseye around his shot.
= Sam shot at a wall, and then painted a bullseye around his shot. = background information about guns and bullets and such.
= background information about guns and bullets and such.