More about Bayes’ theorem; an introduction was given here. Once again, I’m not claiming any originality.
You can’t save a theory by stapling some data to it, even though this will improve its likelihood. Let’s consider an example.
Suppose, having walked into my kitchen, I know a few things.
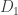
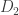

Obviously, 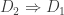


Consider the likelihood of these two theories. Using the product rule, we can write:


Both theories are equally able to place a cake in my kitchen, so 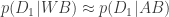


So far, so good, and hopefully rather obvious. Let’s look at two ways to try to derail the Bayesian account.
Details Details
Before some ad hoc-ery, consider the following objection. We know more than
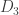
Now, there is no reason to expect my wife to make me a cake with that exact pattern, so our likelihood takes a hit:

Alas! Does the theory that my wife made the cake become less and less likely, the closer I look at the cake? No, because there is no reason for an accidentally delivered cake to have that pattern, either. Thus,

And so it remains true that,

and the wife hypothesis remains the prefered theory. This is point 5 from my “10 nice things about Bayes’ Theorem” – ambiguous information doesn’t change anything. Additional information that lowers the likelihood of a theory doesn’t necessarily make the theory less likely to be true. It depends on its effect on the rival theories.
Ad Hoc Theories
What if we crafted another hypothesis, one that could better handle the data? Consider this theory.

Unlike 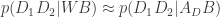
Intuitively, we would think that however unlikely it is that a cake would be accidentally delivered to my house, it is much less likely that it would be delivered to my house and have “Happy Birthday Luke!” on it. We can show this more formally, since 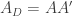
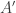
But the statement 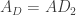




Thus, the product of the likelihood and the prior the same for the ad hoc theory
Too strong?
While all this is nice, it does assume rather strong conditions. It requires that the theory in question explicitly includes the evidence. If we look closely at the statements that make up 



[…] work out. Irrelevant information will be ignored, cumulative cases will naturally grow or decay, vagueness and ad hocness will be punished, and so on. This is why so many scientists and philosophers are so enthusiastic about the Bayesian […]