As background for some future posts, I need to catalogue a few facts about Bayes’ theorem. This is all standard probability theory. I’ll be roughly following the discussion and notation of Jaynes.
Probability
We start with propositions, represented by A, B, etc. These propositions are in fact true or false, though we may not know which. We assume that we can do Boolean things with these propositions, in particular:
-
Conjunction:
means “both A and B are true”
-
Disjunction:
means “at least one of the propositions A, B is true”
-
Negation:
means “not A” (i.e. A is false)
We want to assign probabilities to propositions to represent how likely they are to be true, given the information in other propositions. The function 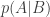



What is p? The older approach to probability of Kolmogorov et al. requires that P satisfy certain axioms. Roughly,
A1.
A2. One means certain: 

A3. Or means add: if at most one of (countable) 
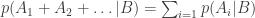
Since the publication of Cox’s Theorem, an alternative approach to probability has gained popularity. Cox (again I’m following Jaynes) proposes the following desiderata of rationality, not as arbitrary axioms but as expectations of any rational approach to reasoning in the face of uncertainty.
D1. Probabilities are represented by real numbers.
D2. Probabilities change in common sense ways. For example, if learning C makes B more likely, but doesn’t change how likely A is, then learning C should make AB more likely.
D3. If a conclusion can be reasoned out in more than one way, then every possible way must lead to the same result.
D4. Information must not be arbitrarily ignored. All given evidence must be taken into account.
D5. Identical states of knowledge (except perhaps for the labeling of the propositions) should result in identical assigned probabilities.
The great advance of Cox’s theorem was to show that one can start with these desiderata and arrive at Kolmogorov’s axioms (at least, for the finite version of A3). Thus, the traditional laws of probability can be applied to more than just frequencies.
Conjunction and Total Probability
Beginning with the desiderata, we can derive more than Kolmogorov’s axioms. There are a number of useful probability identities. Remember that an identity is a formula that holds for any propositions we may substitute in. Here are two preliminary identities, before we get to Bayes’ theorem.
Conjunction: If 

This is the full version of the “and means multiply” rule. Apply recursively for larger conjunctions. Note that B is “along for the ride”, and appears as a given in each term.
Law of Total Probability: We can expand probabilities in terms of some extra information T. We can’t just assume that this extra information is true, obviously, so there is a term that assumes 


Again, B is along for the ride.
Bayes’ Theorem
Here is the usual story about Bayes’ theorem. We have some background information about the world at large, B. We also have some data D about a specific scenario. We want to know: what is the probability that some theory T is true, given the background information and the data? We write this as 

where,
-
The posterior
-
The likelihood
is the probability that D is true given B and T.
-
The prior
is the probability that T is true given only the background information B.
-
The marginal likelihood
is the probability that D is true given only the background information B.
What to do with identities
The purpose of the identities (1) – (3) is to take the probability we want and write it in terms of probabilities we have. For example, we can use equation (2) to write the marginal likelihood in terms of

More generally, we can expand the marginal likelihood using a partition, wherein we have a set of theories 


Nice properties of Bayes’ theorem
-
We can incorporate data piece by piece
-
Theories are rewarded for making data more probable
-
Good theories beat their rivals
-
Sherlock Holmes’ principle: the best theory need not be perfect
-
Ambiguous information changes nothing
-
Nothing new, nothing changes
-
Extraordinary claims require extraordinary evidence
-
Certainty is serious
-
We can compare two theories independently of all others
-
A theory divided against itself will not stand.
1. We can incorporate data piece by piece
Suppose the data D can be split into two: 


The second line has the same form as if we assumed that 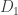

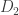
2. Theories are rewarded for making data more likely
Under what circumstances does the probability of T increase when D is added? From Bayes’ theorem,
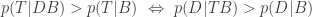
Similarly for “less than”. This is a nice result. If assuming that T is true makes it more likely that D is true, then the addition of D to our knowledge increases the probability that T is true. (It doesn’t follow that T is likely; only that it is more likely with D and B than on B alone.)
3. Good theories beat their rivals
When is a theory more likely than not to be true? Using equation (4),

The important quantity for a theory is the product of its likelihood and its prior. If this product is larger for T than for not-T, that theory is more probable than not. Thus, in evaluating the probability of a theory, we compare it to the set of all of its rivals, not-T.
4. Sherlock Holmes’ principle: the best theory need not be perfect
Note that, for inequality (7) above to hold, neither the likelihood 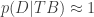
5. Ambiguous information doesn’t change anything
If certain data D is equally probable on

Brendon has made this point quite nicely in a previous post, using the example of a lottery. Note, in particular, that we don’t need to throw away ambiguous information by, say, replacing “John Smith won the lottery” with “someone won the lottery”. Bayes’ theorem automatically filters out what is irrelevant.
6. Nothing new, nothing changes
If knowing B is enough to know D (i.e. if D follows from B) then 


7. Extraordinary claims require extraordinary evidence
This is another corollary of (4), which we can formulate as follows,
If 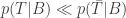


An extraordinary claim is a priori unlikely, hence
Note that an extraordinary claim can be the most probable a posteriori. “Extraordinary claims require extraordinary evidence” is sometimes interpreted as “extraordinary claims can go jump”. Bayes’ theorem won’t allow this. We cannot dismiss theories on their prior alone (unless that prior is exactly zero).
8. Certainty is serious
Bayes’ theorem takes certainty seriously. Probabilities get stuck at zero and one. Given some theory T, if there is some background information B which causes you to assign 

If 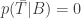

Similarly if 
This doesn’t hold approximately. Probabilities that are nearly one or zero don’t necessarily remain near one or zero when other data is added.
9. We can compare two theories independently of all others
We can consider just two theories as follows,

This is independent of all the other possible theories considered above, since the marginal likelihood cancels out. Restricting our focus to just two theories can obviously be very useful in practice.
10. A theory divided against itself will not stand.
Suppose my theory can be broken up into a number of propositions 

The first term on the right hand side is the one I’m after. 




While an 80+ year old, drainpipe climbing killer explains the evidence (


[…] « 10 Nice things about Bayes’ theorem […]
[…] laid down the basics of probability theory and Bayes’ theorem in a previous post. Here’s the story, as a reminder. We have some background information B and some data D. We want […]
[…] on my series on Bayes’ Theorem, recall that the question of any rational investigation is this: what is […]
[…] about Bayes’ theorem; an introduction was given here. Once again, I’m not claiming any […]
[…] of fine-tuning. The mathematical background and notation of probability theory were given in a previous post, and follow the discussion of Jaynes. (Note: probabilities can be either or , and both an overbar […]
[…] 3 is yes. Bayes’ theorem follows from Cox’s theorem, which assumes only some reasonable desiderata of reasoning. So it is an identity – given any propositions x, y, and z, I can use Equation (4). This is […]
[…] being handed posteriors from the clouds, we use probability identities to break them into manageable pieces. One of those pieces is the likelihood – the probability […]
[…] Bayes’ theorem follows from Cox’s theorem, which assumes only some reasonable desiderata of reasoning. […]
[…] responses to experiences are very similar to Bayesian reasoning. Take trust as an example. If some dudette off the street – let’s call her […]
[…] I’ve noted before, a small likelihood represents an opportunity. We rank hypotheses by their likelihood (probability […]
[…] likelihood punish a theory sufficiently that an alternative theory should be preferred? Go use Bayes’s Theorem! This part of Metaxas argument is actually valid – if the premises are true, an interesting […]
[…] minimales, je vous renvoie donc ceux qui n’ont pas une curiosité mathématique poussée vers un article du chercheur postdoctorat Luke Barnes qui explique très bien pour un public non […]
[…] 10 Nice things about Bayes’ theorem […]