I laid down the basics of probability theory and Bayes’ theorem in a previous post. Here’s the story, as a reminder. We have some background information B and some data D. We want to know: what is the probability that some theory T is true, given the background information and the data? We write this as 
However, this “background information” is a little vague. What puts something in the background? How much background do I need to dig up? How do we divide our knowledge into background information B and data D? Does it matter? Is it that background information is being assumed as known, while for the data, as with all measurements, we must acknowledge a degree of uncertainty?
Here’s a few things about background information.
-
Tell me everything
-
The posterior views data and background equally
-
Calculate probabilities of data, with background information
-
Both background and data are taken as given
-
You should divide K cleanly
1. Tell me everything
The question is this: given everything I know 

In practice, thankfully, irrelevant information can be ignored as it will factor out anyway (Point 5). That gives us the definition of “relevant” in probability theory: a statement is relevant if including it as given changes our probabilities.
2. The posterior views data and background equally
Why, then, have we decided to break up everything we know 

If K contains a great many statements (as it always does) then there will be multiple ways to divide it into “background” and “data”. We could have 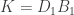

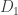
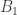
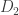



3. Calculate probabilities of data, with background information.
There is a unique posterior probability of T, given K. Thus, any division of K into D and B that allows us to calculate the likelihood, prior and marginal likelihood (i.e. the right hand side of Bayes’ theorem) will do. The question to ask is: how can I divide K into parts such that I can calculate the probability of one part with the other part (and T)? That’s all there is to it – call the first part the “data” and the second part the “background”.
These names – background and data – are simply the way it usually works out practice. I am in principle free to reverse the labels of the background and data. In practice, however, I will usually be unable to calculate the terms of Bayes theorem in this case.
4. Both background and data are taken as given.
Looking again at the terms of Bayes theorem, notice that the background information appears as a given in each term, while two of the terms consider the probability of the data. Does this mean that, while the uncertainty of the data is taken into account, the background is treated as certain for the sake of this calculation?
The discussion above shows that the background and data are simply labels, and thus they cannot have a different status in the calculation. In particular, nothing would change in principle if I reversed the labels.
The posterior
5. You should divide K cleanly
I’ve been assuming that, when apportioning everything you know K into B and D, there is no overlap between the pieces. This is a good idea. Not because it would be wrong – as long as everything is in there somewhere, you’re OK. But you’re wasting your time, because this will happen …
Suppose:
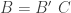
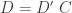
where C represents the common statement which you’ve unwisely left in both B and D. Recall that, in a boolean algebra, AA = A, i.e. if A is true if and only if “A and A” is true. Now, here’s what happens in Bayes theorem, for any theory T:



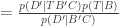

Since D and B are just labels, I could swap them and prove that 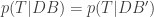

[…] « Bayes’ Theorem: what is this “background information”? […]
[…] on my series on Bayes’ Theorem, recall that the question of any rational investigation is this: what is the […]
[…] pretending that we don’t know whether we exist, or that this fact doesn’t count. See also this post regarding Carrier’s discussion of Collins – if your posterior changes when you move […]
[…] crucially on placing o in b, then something is wrong. I’ve explained this in more detail here. The stuff we label “background” is not special, not the stuff we really know. As […]
[…] life forms, then it is heavily penalised by the falsity of that statement. (We all understand background information, right?) We end up talking about universes without observers because those kind of universes are […]
[…] Instead of adding Evolution to Naturalism as a theory, they decide to add Evolution to our background information (in other words, they’ll say Evolution is common knowledge to everyone; it’s something […]
[…] this example yourself to include more theories). On Monday, the available data implies that their (prior) probabilities are equal. By Friday, new data has arrived from two independent sources (say, […]