Last time, we looked at historian Richard Carrier’s article, “Neither Life nor the Universe Appear Intelligently Designed”. We found someone who preaches Bayes’ theorem but thinks that probabilities are frequencies, says that likelihoods are irrelevant to posteriors, and jettisons his probability principles at his leisure. In this post, we’ll look at his comments on the fine-tuning of the universe for intelligent life. Don’t get your hopes up.
Simulating universes
Here’s Carrier.
Suppose in a thousand years we develop computers capable of simulating the outcome of every possible universe, with every possible arrangement of physical constants, and these simulations tell us which of those universes will produce arrangements that make conscious observers (as an inevitable undesigned by-product). It follows that in none of those universes are the conscious observers intelligently designed (they are merely inevitable by-products), and none of those universes are intelligently designed (they are all of them constructed merely at random). Suppose we then see that conscious observers arise only in one out of every
universes. … Would any of those conscious observers be right in concluding that their universe was intelligently designed to produce them? No. Not even one of them would be.
To see why this argument fails, replace “universe” with “arrangement of metal and plastic” and “conscious observers” with “driveable cars”. Suppose we could simulate the outcome of every possible arrangement of metal and plastic, and these simulations tell us which arrangements produce driveable cars. Does it follow that none of those arrangements could have been designed? Obviously not. This simulation tells us nothing about how actual cars are produced. The fact that we can imagine every possible arrangement of metal and plastic does not mean that every actual car is constructed merely at random. This wouldn’t even follow if cars were in fact constructed by a machine that produced every possible arrangement of metal and plastic, since the machine itself would need to be designed. The driveable cars it inevitably made would be the product of design, albeit via an unusual method.
Note a few leaps that Carrier makes. He leaps from bits in a computer to actual universes that contain conscious observers. He leaps from simulating every possible universe to producing universes “merely at random”. As a cosmological simulator myself, I can safely say that a computer program able to simulate every possible universe would require an awful lot of intelligent design. Carrier also seems to assume that a random process is undesigned. Tell that to these guys. Random number generators are a common feature of intelligently designed computer programs. This argument is an abysmal failure.
How to Fail Logic 101
Carrier goes on …
If every single one of them [conscious observers in simulated universes] would be wrong to conclude that [their universe was intelligently designed], then it necessarily follows that we would be wrong to conclude that, too (because we’re looking at the same evidence they would be, yet we could be in a randomly generated universe just like them).
In other words, if we are in randomly generated universe, then we observe a life-permitting universe. We observe a life-permitting universe. Thus, we are in a randomly generated universe. This is a textbook example of affirming the consequent, a “training wheels” level logical fallacy. That the evidence is consistent with a hypothesis doesn’t mean that the hypothesis must be true.
Don’t Play Poker Like This
It simply follows that if we exist and the universe is entirely a product of random chance (and not NID), then the probability that we would observe the kind of universe we do is 100 percent expected. … The conscious observers in that universe [the only existent universe, just by chance finely tuned to produce intelligent life] would see exactly all the same evidence [as in a multiverse]… The evidence simply always looks exactly the same whether a universe is finely tuned by chance or by design – no matter how improbable such fine-tuning is by chance. And if the evidence looks exactly the same on either hypothesis, there is no logical sense in which we can say the evidence is more likely on either hypothesis. Think of getting an amazing hand at poker: whether the hand was rigged or you just got lucky, the evidence is identical. So the mere fact that an amazing hand at poker is extremely improbable is not evidence of cheating.
False. Obviously false.
Think for half a second about the poker example. Suppose I am dealing, and I deal myself a Royal flush. “No evidence of cheating there”, you think, “since a Royal flush looks the same whether he’s cheating or not”. Then it happens again. And again. It happens 20 times in a row. Unless you’ve crippled your ability to calculate probabilities by subscribing to finite frequentism, you know that the probability of this happening with a fair dealer is 1 in 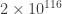
Here’s a free lesson on how to use Bayes’ theorem to analyse this scenario. If the prior probability that I would cheat is 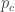


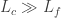
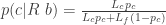
As more Royal flushes are dealt, 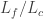

When the Evidence “Looks the same”
Carrier says that “if the evidence looks exactly the same on either hypothesis, there is no logical sense in which we can say the evidence is more likely on either hypothesis”. Nope. Repeat after me: the probability of what is observed varies as a function of the hypothesis. That’s the whole point of Bayes theorem.
For example, the cheating hypothesis and the fair-dealer hypothesis are equally able to put a Royal flush on the table. The evidence looks exactly the same. Given that you cheat in order to win, a Royal flush is much more likely to be dealt if the dealer is cheating. So the evidence is more likely on the cheating hypothesis. This is so blindingly obvious it would usually go without saying. The same evidence E can have different probabilities depending on the hypothesis. The likelihood of E given two different hypotheses 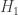

The Firing Squad Machine
Let’s take a look at Carrier’s version of the firing squad analogy. You are placed in a room with a mystery machine that fires bullets. Having fired a large number of bullets, each in a different, seemingly random direction, you are still alive. What should we conclude about the machine?
We know that,
Fn = n bullets have been Fired (n > 0).
M = all the bullets have Missed me.
L = I am still Living
(With a slight abuse of notation, assume any relevant background information B in each probability below).
Two theories we could consider are,
D = the machine is Designed to ensure my survival
I = the machine is Indifferent to my survival
Assume for simplicity that the bullets are cyanide-coated so that any hit will kill. Then
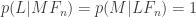
As above, we can prove fairly easily that, given that I am alive, all the bullets must have missed me regardless of whether the machine is designed or indifferent,
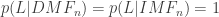
So, given what I know (in particular, M), the probability that I live is one, regardless of whether the machine is designed or indifferent. Does it follow that I have no information at all as to the design of the instrument? Intuitively, I must. If the machine fires 1 million bullets, so that the walls of the room are riddled with bullets except for a perfect outline of my silhouette, surely we’d start to suspect that the machine wasn’t the random killing machine we’d feared. Bayes’ theorem backs this up. We can calculate the ratio of the posterior probabilities of our two theories,
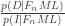

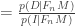

The first term is the ratio of the likelihoods. How likely is it that all the bullets would miss me, given n bullets were fired and the machine is either designed to keep me alive or designed indifferently? Very roughly, if the machine is designed for life then we expect it to do its job, 
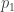
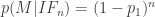

Bayes’ Theorem Omits Redundancies
Something to note from the discussion above. While L is not given in the likelihoods, it is given in the posterior, as the sequence of equals signs show. Thus, the fact that L does not appear in certain terms in the equation does not mean that we are ignoring L, or reasoning as if we didn’t know L, or pretending that L doesn’t count. Put another way – just because something is known, doesn’t mean that it is taken as given in every term in our calculation of the posterior. If that confuses you, read this.
This applies more generally. The equations above show that, given any theory 

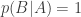

This is true, even though 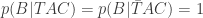

It follows that Carrier’s “formal proof” of his central argument in footnote 23 fails. Applying this to fine-tuning, let:
f = Finely tuned universe
o = intelligent Observers exist
NID = Non-terrestrial Intelligent Design
b = background knowledge
All that follows from the anthropic principle – that observers will observe that they exist in a life-permitting universe 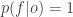


Carrier’s Account of the Firing Squad Machine
Having seen the Bayesian account above, let’s see how Carrier analyses the machine.
Suppose we knew in advance that 1 in 4 such machines was rigged to miss, and that the chance of their missing by accident was 1 in 100. Then we would infer design, because in any cohort of 1,000 victims, on average 250 will survive by design and only 10 will survive by chance, so if you are a survivor your prior odds of having survived by chance are 10 in 260, or barely 4 percent.
In our notation, the prior probability of a rigged machine 
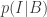
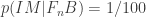
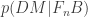
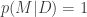
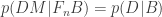

No sign of probability theory competence there, but let’s keep looking.
But suppose you knew in advance that only one in four results was a product of design, and the others were chance. Then in any cohort of a thousand victims you will still know there are on average ten survivors by chance, but you will also know that for every survivor there is who survived by design, there more will have survived by chance, so you know that there can be, on average, only three who survived by design – so if you are a survivor, your odds of having survived by chance are still three in four or 75 percent. In this case, you shouldn’t conclude design, and that’s even knowing the odds of having survived by chance are 1 in 100.
Lesson 1: 78 words in a sentence is too many, especially if it includes the conjunction “so” twice, one “but” and an ill-advised em dash.
The reason why Carrier’s confusion between prior and posterior in the previous paragraph is more than a notational blunder is that he now tries to change the posterior. We saw in a previous post why simply announcing a posterior probability is backwards, unBayesian and unrealistic. But now it’s even worse. Carrier effectively announces that the posteriors have a certain ratio 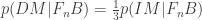
As in the previous post, we can calculate the probabilities that Carrier is assuming behind the scenes. Since 
Conclusion
Here’s why this matters, and with this Carrier’s essay finally bleeds to death.
[In] our background knowledge, we have no evidence that the frequency of very improbable events (not already caused by known life) being products of NID is anything higher than 25 percent. It doesn’t matter how improbable any of those events are. … Thus we cannot conclude that the probability that the universe is a product of NID is anything higher than its prior probability of 25 percent.
The whole point of Carrier’s analysis of the firing squad machine was that you can ignore the prior only in the case where you, clairvoyantly, specify the posterior. So Carrier’s argument from background evidence and the prior probability misses his own point. Unless Carrier can magically pull the posterior probability of NID from his posterior, he’s going to have to deal with Bayes’ theorem. The posterior is only equal to the prior if the likelihood of NID is equal to the likelihood of ~NID. As we saw above, this does not follow from the anthropic principle. Carrier’s argument fails.
The probability of ~NID depends on the probability of a life-permitting universe existing “by chance”. If it is very small, as fine-tuning suggests, then the probability of ~NID may also be very small. Carrier’s compendium of elementary logical and probabilistic blunders does nothing to turn back the force of the fine-tuning argument. If you want to read a decent critique of the argument, try Sean Carroll, Paul Davies, Alex Vilenkin, Leonard Susskind, Bradley Monton, or perhaps someone who actually understands physics, cosmology and probability.

[…] What Chance Looks Like – A Fine-Tuned Critique of Richard Carrier (Part 2) […]
[…] Bayes’ Theorem: Ad Hoc-ness and Other Details What Chance Looks Like – A Fine-Tuned Critique of Richard Carrier (Part 2) […]
I’m curious LUke, how would you feel about the probability of the royal flushes being a result of cheating if no cheating had ever been observed in any field ever and if no mechanism for cheating had ever been demonstrated or even proposed?
Good question. A few points:
* Not zero! Definitely not zero. Remember that probabilities get stuck at zero (https://letterstonature.wordpress.com/2013/10/26/10-nice-things-about-bayes-theorem/) so if we say zero then we’re saying that no possible future evidence could convince us that someone was cheating.
* Given that the prior is not zero, there is some sequence of Royal flushes that would render the cheating hypothesis more probable than the fair dealer hypothesis. Mathematically, given some p_c > 0 there is some n such that p(Cheating | n Royal flushes) > 1/2 .
* The problem of assigning prior probabilities is an open area of research which I’m not going to solve in a blog comment. I’d probably have a better idea if I’d attended http://www.maxent2013.org , which Brendon is organising and attending. There are various ideas: Jeffreys priors, MaxEnt, and a load of others I don’t really understand.
what would be wrong in saying its not definable? I’ve kind of given a scenario that’s as close to “nothing to go on” as I can imagine. Do we still think probabilities are meaningful in this scenario?
The problem is this. I’m calculating p(T | K). K is everything I know. Bayes theorem is an identity, so I should be able to divide K into whatever pieces I like and still get the same result. (See previous posts, e.g. https://letterstonature.wordpress.com/2013/11/17/bayes-theorem-what-is-this-background-information/)
Thus, if there is a certain division of K that results in the prior being “undefined”, then assuming that “undefined (plus/minus/times/divided by) anything = undefined”, then Bayes’ theorem tells us that the posterior is undefined. So an undefined prior ruins everything, even if later evidence E gives strong support for the hypothesis.
I think the moral of the story here is that some probabilities are difficult to calculate and require a bit of thought. If we give up and say “undefined”, then we lose the ability to update our prior when new information arises. The alternative is to put some restrictions onto our division of K into E and B, but this I think is an ugly and probably arbitrary option to take.
Impressive critiques Luke and thorough as usual 🙂 After reading this and other comments from you I tend to be more skeptical on the things Richard Carrier writes.
In a recent article ( http://freethoughtblogs.com/carrier/archives/4973 ) by Richard Carrier criticizing William Lane Craig he expands his thoughts on fine-tuning:
“In particular he claims “the fundamental constants and quantities of nature must fall into an incomprehensibly narrow life-permitting range,” but that claim has been refuted–by scientists–again and again.
We actually do not know that there is only a narrow life-permitting range of possible configurations of the universe. As has been pointed out to Craig by several theoretical physicists (from Krauss to Stenger), he can only get his “narrow range” by varying one single constant and holding all the others fixed, which is simply not how a universe would be randomly selected. When you allow all the constants to vary freely, the number of configurations that are life permitting actually ends up respectably high (between 1 in 8 and 1 in 4: see Victor Stenger’s The Fallacy of Fine-Tuning).
And even those models are artificially limiting the constants that vary to the constants in our universe, when in fact there can be any number of other constants and variables, which renders it completely impossible for any mortal to calculate the probability of a life-bearing universe from any randomly produced universe. As any honest cosmologist will tell you. (As well as honest Christians: see Timothy McGrew, Lydia McGrew, and Eric Vestrup, “Probabilities and the Fine-Tuning Argument: A Sceptical View,” in Mind 110.440 [October 2001]: 1027-37.) Yet, all the scientific models we have (which follow from what we do know, and allow all constants to vary freely) show life-bearing universes to be a common result of random universe variation, not a rare one.
We also do not know this is the only universe. There may have been innumerable universes formed and collapsed before transforming into ours, or there may be innumerable universes co-existing with or extending from ours, or both. And we needn’t merely conjecture their innumerability: leading cosmological theories already entail, even from a single simple beginning, the formation of innumerable differently-configured regions of the universe. This is the inevitable consequence of Chaotic Inflation Theory, for example, the most popular going theory in cosmological physics today. But will Craig tell his readers that? No.
In fact, even without presuming Chaotic Inflation, an endless series of universes is already entailed by present science. Most configurations of constants produce either a collapsing universe (which re-explodes, by crunch or bounce, rolling the dice all over again, so those configurations must be excluded from any randomization ratio) or a universe that accelerates its expansion until it rips apart (as its energy density approaches infinity, which results in another Big Bang, rolling the dice all over again, so those configurations must also be excluded from any randomization ratio) or a universe in between (most of which are life friendly). But even universes in between, if all universes are governed by quantum mechanics, then a Big Bang always has a very small but nonzero probability of occurring. Yet all nonzero probabilities approach 100% as time increases. So even a universe that just coasts along or reaches a future heat death will inevitably end in another Big Bang (after many billions of trillions of years).
That means every possible configuration of constants–every single possible configuration–ends in a reset, a new Big Bang, which re-randomizes those constants. This means, if quantum mechanics is true in all universes and all Big Bangs randomize constants, then our universe has a probability of existing of 100%. It is that certain even if time had a beginning and is not past-eternal. Then our universe will arise a very long time after the first moment of time, having undergone countless transformations (past Big Bangs). But that means we should assume that’s what happened, since it’s 100% exactly what would happen if all that were true is that quantum mechanics governs all universes (which we have no reason presently to doubt) and the constants of a universe are selected at random in any Big Bang (which Craig must suppose, in order to claim they would only arise at random in the absence of a god). And that’s a much simpler explanation than “a super-amazing spirit-mind did it.”
“
I think it’s strange by the way that he objects to WLC “not telling his readers” about other opposing views, while he himself refer to Victor Stenger and his work without “telling his readers” about the works by you and Robin Collins criticising Victor Stenger for example.
As has been pointed out to Craig by several theoretical physicists (from Krauss to Stenger), he can only get his “narrow range” by varying one single constant and holding all the others fixed, which is simply not how a universe would be randomly selected. When you allow all the constants to vary freely, the number of configurations that are life permitting actually ends up respectably high (between 1 in 8 and 1 in 4: see Victor Stenger’s The Fallacy of Fine-Tuning).
I’ll give you the link so that Luke doesn’t have to:
Note that it’s unnecessary to quote the entire thing as long as the link is there.
[…] « What Chance Looks Like – A Fine-Tuned Critique of Richard Carrier (Part 2) […]
Hope you had a nice Christmas Luke. Thanks you for your reply. A problem I have is that I don’t see why saying undefined now means giving up. Nor do I see why we cant go from undefined to defined as our knowledge increases. Whats wrong with acknowledging our current ignorance and trying to improve upon the situation? Lastly whilst I agree the probability of cheating is not necessarily zero if we have never seen any one cheat and have no known mechanisms for cheating. However whether it is zero or not, is obviously not the question. The questions is, is cheating now more likely than the fair dealer hypothesis?
If we live in a world where we have observed people cheat or even if we have never observed it but at least knwo its theoretically possible then it seems obvious as you rightly point out that the cheating hypothesis is more likely than the fair dealer. However if we live in a world where we have never seen anyone cheat ever and we have no known mechanism whereby someone can cheat and lets also throw in that we do not know any motives for the dealer then to me it is not so clear at all which is more likely.
Nor do I see why we cant go from undefined to defined as our knowledge increases.
And how could our knowledge conceivably increase?
A short answer … I’m on holidays …
“And how could our knowledge conceivably increase?”. Learning new things. In probability notation, a new statement E which we can take as given.
Bumper:
If probabilities can go from undefined to defined as knowledge increases, then we must restrict the domain of applicability of Bayes theorem. It would no longer be an identity, true of any propositions.
For example, suppose we know E and B. We want to calculate the probability of T. Suppose that we conclude that B is not enough information, and so the prior p(T | B) is undefined. Suppose further that E and B together is enough for the posterior p(T | EB) to be defined. Now, suppose in this particular problem that the likelihoods p(E | TB) and p(E | ~TB) are defined. Then we could rearrange Bayes theorem and calculate the prior p(T | B) after all.
How do we avoid this contradiction? We are free to pick T and ~T at will in this example, so I don’t think that we can hope that the likelihoods will be similarly undefined. We just have to say that Bayes theorem simply does not hold in this case. We would need a new desiderata of probability theory to tell us under what circumstances Bayes theorem would apply. I’m open to suggestions, but one is heading for a vaguer, uglier theory.
If we don’t know of any motives to cheat then that is a different problem entirely, since its not cheating. Given no preference for one deal over another, such a “cheater” wouldn’t be any different from chance. there would be no difference between the likelihoods.
Learning new things. In probability notation, a new statement E which we can take as given.
And what is it that convinces us that E is true? Do we reason that P(E|A)=1, where A is something we know? Did we arrive as “we know A” by reasoning P(A|B)=1, where B is somethign we know? It seems that this chain has to stop somewhere, at a set of assumptions that we simply take for granted. We will most likely have to allow for these assumptions to be falsified later on, so why not start of with “The probability of cheating is P” with a fairly arbitrary parameter P and go from there?
A very good point, to which I think I have a good answer:
Your thoughts?
In practice, one usually hopes that the data will swamp the prior i.e. that the data is good enough to make the calculation robust, invariant to reasonable changes in the prior.
In Proving History, Richard Carrier applies Bayes’ Theorem to the claim that someone has been struck by lightning. Carrier says that the prior probability is not the probability that someone has been struck by lightning but the probability that someone tells the truth in such cases. This seems to be another case of by-passing Bayes’ Theorem.
What happens if we don’t by-pass Bayes’? The lifetime risk of being hit by lightning is 1 in 6000. Let’s say that in general one statement in a thousand is a lie. So if 6000 people claim to have been hit by lightning, one will be telling the truth and six will be lying. Therefore, we shouldn’t believe someone who claims to have been hit by lightning. It’s worse in the case of the lottery. If 14 million people claim to have won the lottery, one will be telling the truth and 14000 will be lying.
It could be that the chances of lying are very different in different circumstances. In that case we need to have a much greater understanding of people’s behaviour in these cases before we can use Bayes’ Theorem.
“So if 6000 people claim to have been hit by lightning, one will be telling the truth and six will be lying”. What about the other 5993? Were they struck or not?
Yes, sorry. That was a bad way of putting it. The prior probability of being hit by lightning is 1 in 6000. The likelihood that someone who claims to have been hit by lightining is telling the truth is 99.9% – on the grounds that only one in a thousand statements in general is a lie. So the posterior is 14%.
Ok. Take 6,000 people. On average …
1 has been struck by lightning.
6 decide to lie about being struck by lightning.
So the probability of telling the truth about being structure by lightning is
1 / (1 + 6) = 14%.
That doesn’t make much sense. “1 in 1000 statements in general is a lie” does not imply that “1 in 1000 people will lie about having been struck by lightning”. That’s a very specific lie.
There’s a question of selection effects here. Did you go poll 6000 people at random and ask them whether they had been struck by lightning? Or did we ask 6000 people “has anything amazing happened to you?” and 6 people decided to lie about being struck by lightning? These are very different cases.
Probability theory is subtle!
Thanks for explaining things. There are undoubtedly people that would lie about being hit by lightning but don’t because the idea doesn’t occur to them. Of course, if there was a highly publicised case of a celebrity being hit by lightning then you would probably find a lot of people going out of their way to lie about it.
By the way, what Richard Carrier actually said in Proving History was that if someone claims to have been hit *five* times by lightning the prior probability is not the prior probability of being hit five times but the probability that someone is telling the truth in such cases. Therefore, I don’t think he should have been calling twenty royal flushes a straw man.
[…] my three critiques (one, two, three) of Richard Carrier’s view on the fine-tuning of the universe for intelligent life, we […]
[…] to GGDFan777 for the tip-off: Jeffery Jay Lowder has weighed in on my posts (one, two, three, four) about Richard Carrier. It’s in the comments of this post over at The Secular […]
[…] Dr. Barnes wrote a four part series on his blog critiquing that essay by […]
“If Carrier actually believes that, then I’d love to play poker with him.”
Nice; you took the words right out of my mouth.
I know this is an old post but in case anyone’s listening…
There seems to be a mistake here.
The following is a sound argument:
Premise: The probability of being dealt a straight flush by a fair dealer is identical to the probability of being dealt the hand 2h, 3s, 7s, jd, qd by a fair dealer.
Premise: The probability of being dealt the hand 2h3s7sjdqd does not constitute evidence of a non-fair dealer should such a hand actually be dealt.
Conclusion: The probability of being dealt a straight flush does not constitute evidence of a non-fair dealer should such a hand actually be dealt.
(In other words, briefly: Since the probabilities of the two hands are identical, it cannot be probability alone which makes it right to suspect cheating.)
But you have insisted that the probability of being dealt a straight flush DOES constitute evidence of cheating should such a hand actually be dealt.
You can’t be right–as the mantra goes, the conclusion of a sound argument is always true, and what you’ve said contradicts that true conclusion.
But have you misspoken?
The point is that there is no such thing as “the” probability of the hand. There is the probability of a given hand *given* that the dealer is dealing fairly, and the probability of the hand *given* that the dealer is cheating.
The probabilities of each hand *given fairness* are equal, so these two probabilities alone do not constitute evidence of cheating. That is the correct conclusion of your argument. But no Bayesian would reason this way – this is frequentist-style. The probabilities of each hand given cheating are not equal, and this can be used as evidence of cheating.
As always, put it in Bayes theorem!
But all Carrier said, which you quoted and then said “Wrong, obviously wrong,” was that the low probability itself doesn’t constitute evidence of cheating.
Yet here you explicitly agree with that statement.
I should have been clearer. The sentence that is false is: “And if the evidence looks exactly the same on either hypothesis, there is no logical sense in which we can say the evidence is more likely on either hypothesis. Think of getting an amazing hand at poker: whether the hand was rigged or you just got lucky, the evidence is identical.”
Okay, that clears it up.
Sorry–in the above argument, in the first premise, it should refer to the probability of being dealt some particular straight flush, say 10h jh qh kh ah.
Gosh, the same edit should be made in the conclusion too of course!
[…] January 2014, I finished a series of four posts (one, two, three, four) critiquing some articles on fine-tuning by Richard Carrier, including one titled […]
[…] a guy who doesn’t know what a prior probability is. Given that he has previously confused priors and posteriors, he’s zero from three on the fundamentals of Bayes theorem. You cannot keep getting the […]
[…] https://letterstonature.wordpress.com/2013/12/15/what-chance-looks-like-a-fine-tuned-critique-of-ric… […]