After a brief back and forth in a comments section, I was encouraged by Dr Carrier to read his essay “Neither Life nor the Universe Appear Intelligently Designed”. I am assured that the title of this essay will be proven “with such logical certainty” that all opposing views should be wiped off the face of Earth.
Dr Richard Carrier is a “world-renowned author and speaker”. That quote comes from none other than the world-renowned author and speaker, Dr Richard Carrier. Fellow atheist Massimo Pigliucci says,
The guy writes too much, is too long winded, far too obnoxious for me to be able to withstand reading him for more than a few minutes at a time.
I know the feeling. When Carrier’s essay comes to address evolution, he recommends that we “consider only actual scholars with PhD’s in some relevant field”. One wonders why, when we come to consider the particular intersection of physics, cosmology and philosophy wherein we find fine-tuning, we should consider the musings of someone with a PhD in ancient history. (A couple of articles on philosophy does not a philosopher make). Especially when Carrier has stated that there are six fundamental constants of nature, but can’t say what they are, can’t cite any physicist who believes that laughable claim, and refers to the constants of the standard model of particle physics (which every physicist counts as fundamental constants of nature) as “trivia”.
In this post, we will consider Carrier’s account of probability theory. In the next post, we will consider Carrier’s discussion of fine-tuning. The mathematical background and notation of probability theory were given in a previous post, and follow the discussion of Jaynes. (Note: probabilities can be either 


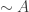
Probability theory, a la Carrier
I’ll quote Carrier at length.
Bayes’ theorem is an argument in formal logic that derives the probability that a claim is true from certain other probabilities about that theory and the evidence. It’s been formally proven, so no one who accepts its premises can rationally deny its conclusion. It has four premises … [namely P(h|b), P(~h|b), P(e|h.b), P(e|~h.b)]. … Once we have [those numbers], the conclusion necessarily follows according to a fixed formula. That conclusion is then by definition the probability that our claim h is true given all our evidence e and our background knowledge b.
We’re off to a dubious start. Bayes’ theorem, as the name suggests, is a theorem, not an argument, and certainly not a definition. Also, Carrier seems to be saying that P(h|b), P(~h|b), P(e|h.b), and P(e|~h.b) are the premises from which one formally proves Bayes’ theorem. This fails to understand the difference between the derivation of a theorem and the terms in an equation. Bayes’ theorem is derived from the axioms of probability theory – Kolmogorov’s axioms or Cox’s theorem are popular starting points. Any necessity in Bayes’ theorem comes from those axioms, not from the four numbers P(h|b), P(~h|b), P(e|h.b), and P(e|~h.b).
Nevertheless, with Bayes’ theorem in hand, we need to calculate probabilities. How do we go about this? What is a probability? Discussing NID = non-terrestrial intelligent design, Carrier says,
What is the prior probability of NID? … Probability measures frequency (whether of things happening or of things being true). So we’re really asking how frequently are things we point to (in all our background knowledge) the product of NID? Quite obviously, very infrequently indeed. In fact, so far, that frequency is exactly zero. … If we set aside all contested cases (and take them all out of b and put them in e, so we can deal with them later – which means any alleged design of the universe, the first life, or current life), what do we have left? Not a single case of NID. And countless billion and trillions of cases of not NID. … Thus, based on our background knowledge alone, in other words, before we consider any as-yet-only-alleged cases of NID, the frequency of NID is practically infinitesimal (if not, in fact, zero). This means its prior probability is vanishingly small, approaching zero.
It is important to look past the application to NID and identify Carrier’s probabilistic method. He says later,
For example, if 1 in 100 lottery wins are by design, and the remainder by chance, then the probability that an observed win is by design is simply 1 in 100, no matter how improbable that win is. Even if the odds of winning were 1 in
. For even then, if it’s still the case that 99 in 100 wins are the product of chance, then the odds that this win is the result of chance are not 1 in
Let’s summarise Carrier’s approach to probability theory.
Finite Frequentism: Probabilities are frequencies. To calculate the probability of A given B, we count the number (


I will argue that finite frequentism undermines any attempt to construct a useful theory of probability, and that Carrier fails to consistently apply this principle.
The Reference Class
For an overview of finite frequentism and other interpretations of probability theory, see the Stanford Encyclopedia of Philosophy. It is the version of probability I was taught in high school – “favourable over possible”. Given the turf war between frequentists and Bayesians, it is baffling to see someone who has written and lectures on Bayes’ theorem and its application to history blithely espousing a frequentist view of probabilities.
Crucial to this approach is the idea of a reference class – exactly what things should we group together as A-like? This is the Achilles heel of finite frequentism. Suppose Bob wins the lottery. The finite frequentist asks: what fraction of lottery wins in the past have been by cheating? Before we can answer that, we must ask: what counts as a lottery? Does any raffle, bingo or scratchcard count? Should we consider all gambling? If we widen our reference class too much, then we will include games that are easier to rig than your typical lottery, with its televised drawing of the balls etc. We will then overestimate the probability of Bob winning the lottery by design.
It gets even worse if our reference class is too narrow. Should we only consider lotteries with the same choice structure (e.g. 6 choices from 49 balls)? Should we only consider lotteries with the same degree of security? From the same company? Using the same official inspector? The same ball-choosing machine? That were won by Bob? Every event is unique if we give enough details about it. Remembering that the event in question can’t be counted as a known type of thing (we don’t know whether Bob cheated or not), the probability of Bob cheating is formally 0/0. Thus, in the absence of a robust account of the construction of reference classes, finite frequentism fails in every case to assign a probability.
This illustrates the problem with reference classes in general. It requires us to look at everything we know about the case in hand (Bob winning the lottery) and decide a priori what information is reference-class-defining and what must be ignored. The finite frequentist is caught in no-man’s land. Taking into account potentially relevant information requires narrower and narrower reference classes, but the restriction to actual, known cases means that we will eventually run out of cases. Finite frequentism either gives an answer a blunt question, or gives the answer 0/0 to a precise question.
You can see why, in this context, Carrier’s point about moving contested cases from evidence e to background b won’t gel with finite frequentism. If we are free to move every relevant case into e, then the prior probability is either 0 or 0/0. In which case, by Bayes’ theorem, the probability of anything is either undefined or zero.
You may be wondering: why measure frequencies of populations at all? Facts about finite relative frequencies are evidence on which we can base probability calculations. As Jaynes says (pg 155), “[A] probability is not the same thing as a frequency; but, under quite general conditions, the predictive probability of an event at a single trial is numerically equal to the expectation of its frequency in some specified class of trials.”
Actual Probabilities
Further problems follow from the restriction to actual, known cases. Note that both “actual” and “known” are essential – hypothetical cases, and actual but unknown cases cannot be counted. The problem is that the method can never get started. Consider the first ever lottery. Alice wins. What is the probability that she cheated (i.e. won by design)? We have no other cases to consult, so we cannot calculate the probability that Alice cheated. So we cannot say whether Alice cheated or not. Now, Bob wins the second lottery. We have no known cases of cheating in a lottery, so the probability that Bob cheated is 0 out of 1. So we can say with certainty (probability equal to 1) that Bob did not cheat. Christine wins the third lottery. There are no known cases of cheating so the probability that Christine cheated is 0 out of 2. So Christine certainly didn’t cheat. And so on. No one ever cheats in the lottery! Note that adding more information about the circumstances of Christine’s win (she was seen tampering with the ball-choosing machine, is the girlfriend of the official, her ticket is handwritten in crayon) only makes things worse, since there are a fortiori no other events in that reference class.
This is related to the ‘problem of the single case’. The restriction to known, actual events creates an obvious problem for the study of unique events. A few examples.
Cosmology is impossible: Cosmology is the study of the universe as a whole. What is the prior probability that the universe would have a baryon density parameter in the range ![\Omega_b \in [0.01, 0.1]](https://s0.wp.com/latex.php?latex=%5COmega_b+%5Cin+%5B0.01%2C+0.1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
(What cosmologists actually do is assign a uniform probability distribution over some range in 
Scientific discovery is impossible: The LHC observed a series of particle interactions. What is the probability that they observed the Higgs Boson? Well, how many times in our past experience has such a series of particle interactions been known to indicate the presence of the Higgs Boson? None. Thus, the probability that the LHC discovered the Higgs is zero. More generally, the probability of observing anything we haven’t seen before is either zero or undefined. This applies a fortiori to unique events in the history of the cosmos – the origin of life on earth, the extinction of the dinosaurs, the formation of the moon, cosmic reionization, the decoupling of the CMB, the cambrian explosion, etc.
History is impossible: It is baffling that, of all the people to be advocating finite frequentism, Carrier is a historian. Given the documentary and archaeological evidence, what is the probability that Caesar crossed the Rubicon in 49 BC? Well, how many times in our past experience has that evidence been associated with a known case of Caesar crossing the Rubicon? None out of none. Thus, the probability that Caesar crossed the Rubicon in 49 BC is undefined. Broadening the reference class would be subjective and arbitrary – to which other events in history should we compare? In general, all historical hypotheses that invoke unique events have undefined probability. That includes all historical hypotheses (since time is linear and thus all events are unique), and thus the study of history is impossible given Carrier’s approach to probability.
Inconsistency with Finite Frequentism
Carrier, perhaps realising the failure of finite frequentism, abandons it on a number of occasions. He tries to avoid the conclusion that never-before-seen events have probability 0 or 0/0 by stating that the prior probability of NID “approaches zero”. But any probability assignment represents an abandonment of finite frequentism.
Carrier takes as “background knowledge” relevant to the hypothesis that aliens are able to create other universes the fact that “[w]e already can envision ways in which creating designer universes will enter the purview of such [an advanced] species”. No sign of frequencies there.
Carrier completely abandons finite frequentism when he comes to discuss the multiverse. He says,
[The multiverse] hypothesis has an extremely high prior probability: in our background knowledge we have no knowledge of any law of physics that would prevent there being other universes (and no means of seeing if there are none), so the probability that there are is exactly what that probability would be if the number of universes that exist were selected at random.
Needless to say, Carrier has discarded the idea that probabilities are frequencies. What Carrier should have said was “how frequently are things we point to (in all our background knowledge)” the product of N universes? If you are a finite frequentist, the probability of there being more than one universe is exactly zero, since only one universe has been observed. Or perhaps the probability is 0/0, since we are counting the number of known, actual physical realities other than our own which contain more than one universe. Whatever interpretation of probability that Carrier is applying to the multiverse, it isn’t the same one that he applies to fine-tuning. I suspect that is by design.
Forgetting Bayes’ Theorem
After all the build up about the importance of Bayes’ theorem, Carrier doesn’t use it. To remind ourselves, Carrier says that “if we know that less than 1 in 1,000 amazing hands are rigged, and then draw an amazing hand that is 100,000 to 1 against, the probability of that hand being rigged is still only 0.1 percent (1 in 1,000), not 99.999 percent”. Note the vagueness of the reference class again – what counts as an amazing hand?
Let’s analyse this scenario with a bit of formalism. Let c be the cheating hypothesis, f be the fair dealer hypothesis, b be the background information, and e tells us that an amazing hand was dealt. Assume for simplicity that c = ~f. To be consistent with Carrier’s choice of reference class, we throw away any other potentially relevant information (the exact hand dealt, any tells of the player, the fact that you saw him produce an ace from his sleeve). Consider the following terms in Bayes’ theorem.

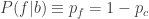
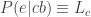
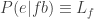

Note that P(e|cb) and P(e|fb) are the probability of any amazing hand, not this particular amazing hand. Carrier states that 
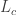
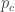
At this point Carrier, bafflingly, bypasses Bayes. We are told that P(c|eb) = 1/1000. It is not calculated from the likelihood and the prior. It is simply announced. This is not the Bayesian approach. There is no use of Bayes’ theorem, or indeed any probability identities. One calculates the posterior P(c|eb) by counting cases in past experience.
We can fill in the details that Carrier omits. By rearranging Bayes’ theorem, we can work out the prior probability that must be assumed in order for the posterior to be as Carrier says. Do the algebra yourself … the answer is 
It’s even worse in the lottery case, where Carrier must assume that, prior to the lottery being drawn, the probability of a particular person winning by cheating is 
Carrier is trying to claim that the likelihood of e on f is irrelevant, no matter how small it is. This is only true because he has pulled the posterior out of nowhere. He has not calculated it using Bayes’ theorem. This is very unrealistic. We almost never have the posterior handed to us on a platter. We need to calculate it by breaking it up into pieces we can estimate, and then combining those pieces using probability theorems. If we are using Bayes’ theorem, the likelihood of each hypothesis is extremely relevant.
Carrier is trying to blunt the impact of the very small numbers that come out of fine tuning. These numbers are our best estimate for the likelihood of a life-permitting universe given “chance”. Don’t worry about that, he says, it’s only the posterior that matters. But we almost always calculate the posterior using Bayes’ theorem, and so it depends on the likelihood. All things being equal, as the likelihood drops, so does the probability of the chance hypothesis. It is farcical for someone who presents himself as a Bayesian to argue that the likelihood of a hypothesis doesn’t matter.
Conclusion
This is from a guy who has lectured on Bayes’ theorem (heaven help those students) and written books and articles with “Bayes’ theorem” in the title. Carrier’s faults are not slips of notation, minor technicalities or incorrect arithmetic. While presenting himself as a modern Bayesian, he is actually a finite frequentist, subscribing to an outdated, overly restrictive and practically useless interpretation of probability. He offers no defence of finite frequentism, fails to mention its tension with Bayesianism and ignores its clear failure to account for probability as it is used in cosmology (relevant to fine-tuning), scientific discovery, and history (Carrier’s own field). Carrier can’t even apply his own half-baked ideas consistently, abandoning them when convenient.
Further, when the time comes to demonstrate the use of Bayes’ theorem, Carrier bypasses it. He tries to argue that likelihoods are irrelevant to posteriors. The whole point of Bayes’ theorem is to use likelihoods (and priors) to calculate posteriors. No scientist, no statistician does probability like this, and for good reason.
Next time, we’ll look at Carrier’s response to fine-tuning. Things don’t get much better.

“Whatever interpretation of probability that Carrier is applying to the multiverse, it isn’t the same one that he applies to fine-tuning. I suspect that is by design.”
😀
[…] « Probably Not – A Fine-Tuned Critique of Richard Carrier (Part 1) […]
[…] Probably Not – A Fine-Tuned Critique of Richard Carrier (Part 1) […]
[…] I was done with Richard Carrier’s views on the fine-tuning of the universe for intelligent life (Part 1, Part 2). And then someone pointed me to this. It comes in response to an article by William Lane […]
[…] my three critiques (one, two, three) of Richard Carrier’s view on the fine-tuning of the universe for intelligent […]
[…] to GGDFan777 for the tip-off: Jeffery Jay Lowder has weighed in on my posts (one, two, three, four) about Richard Carrier. It’s in the comments of this post over at The […]
[…] Dr. Barnes wrote a four part series on his blog critiquing that essay by […]
Reblogged this on Research Reviews and commented:
It seems the internet is flooded with various misuses of Bayes’ Theorem (typically, without actual use of Bayes’ Theorem per se, but rather Bayesian inference/analysis). It proves there is a god, there isn’t a god, that the universe is fine-tuned, that it isn’t, that Jesus rose from the dead, that Jesus didn’t exist, etc. Some popular treatments are better than others, but I thought it might be nice to contrast a technical treatment in a “tier 1” science journal to even a good online treatment. Spiegel, D. S., & Turner, E. L. (2012). . Proceedings of the National Academy of Sciences, 109(2), 395-400.
[…] 2013 Luke Barnes posted a two part critique of Carrier’s chapter, as part of a long series critiquing different people’s statements […]
[…] is “not just like theoretical physics, it is theoretical physics.” He also has an excellent blog dealing with the limitations of finite […]
[…] January 2014, I finished a series of four posts (one, two, three, four) critiquing some articles on fine-tuning by Richard Carrier, including […]
[…] is “not just like theoretical physics, it is theoretical physics.” He also has an excellent blog dealing with the limitations of finite […]
[…] https://letterstonature.wordpress.com/2013/12/13/probably-not-a-fine-tuned-critique-of-richard-carri… […]
[…] Myers makes another observation that I have noted in the past before. The people attracted to Mythicism seem to have a strangely binary way of thinking, whereby things are either black or white, with little to no nuance. So if any of the Jesus stories are not historical (e.g the miracles or the resurrection) then all of them must be completely rejected. I discuss this false dichotomy elsewhere (see “Jesus Mythicism 8: Jesus, History and Miracles“), and it represents a historiographical naïveté, given that history is all about nuance and degrees of likelihood. Again, Mythicism seems to attract people who can only think in absolutes and even those who think historical analysis can be reduced to a kind of calculus: here, again, we find Richard Carrier and his wrongheaded misapplications of Bayesian Probability. […]